Phocolink
Mạng Nơ-ron, Đa tạp và Tô-pô học
Đăng ngày 6 tháng 4 năm 2014
Chủ đề: tô-pô học, mạng nơ-ron, học sâu, giả thuyết đa tạp
Gần đây, có rất nhiều sự hứng khởi và quan tâm đến các mạng nơ-ron sâu vì chúng đã đạt được những kết quả đột phá trong các lĩnh vực như thị giác máy tính.
Tuy nhiên, vẫn còn một số mối lo ngại về chúng. Một trong số đó là việc hiểu thực sự một mạng nơ-ron đang làm gì có thể khá thách thức. Nếu ta huấn luyện tốt, nó đạt được kết quả chất lượng cao, nhưng khó hiểu bằng cách nào nó làm được điều đó. Nếu mạng thất bại, cũng rất khó để hiểu điều gì đã xảy ra.
Mặc dù việc hiểu hành vi của các mạng nơ-ron sâu nói chung là khó, nhưng việc khám phá các mạng nơ-ron sâu có số chiều thấp — tức là các mạng chỉ có vài nơ-ron trong mỗi lớp — lại dễ hơn nhiều. Thực tế, ta có thể tạo ra các hình ảnh trực quan để hiểu hoàn toàn hành vi và quá trình huấn luyện của những mạng như vậy. Góc nhìn này cho phép ta có trực giác sâu hơn về hành vi của mạng nơ-ron và quan sát một mối liên hệ nối kết mạng nơ-ron với một lĩnh vực toán học gọi là tô-pô học.
Từ đó dẫn đến một số điều thú vị, bao gồm cả các giới hạn dưới cơ bản về độ phức tạp của một mạng nơ-ron có khả năng phân loại một số tập dữ liệu nhất định.
Một Ví Dụ Đơn Giản
Hãy bắt đầu với một tập dữ liệu rất đơn giản: hai đường cong trên một mặt phẳng. Mạng sẽ học cách phân loại các điểm thuộc về đường này hay đường kia.
Cách hiển nhiên nhất để trực quan hóa hành vi của một mạng nơ-ron — hay bất kỳ thuật toán phân loại nào — là chỉ đơn giản xem nó phân loại mọi điểm dữ liệu có thể như thế nào.
Ta bắt đầu với lớp mạng nơ-ron đơn giản nhất có thể: chỉ có một lớp đầu vào và một lớp đầu ra. Mạng như vậy chỉ đơn giản cố gắng tách hai lớp dữ liệu bằng cách chia chúng bằng một đường thẳng.
Loại mạng đó không thú vị lắm. Các mạng nơ-ron hiện đại thường có nhiều lớp nằm giữa đầu vào và đầu ra, gọi là các lớp “ẩn”. Ít nhất chúng có một lớp ẩn.
Như trước, ta có thể trực quan hóa hành vi của mạng này bằng cách xem nó làm gì với các điểm khác nhau trong miền của nó. Nó tách dữ liệu bằng một đường cong phức tạp hơn so với một đường thẳng.
Với mỗi lớp, mạng biến đổi dữ liệu, tạo ra một biểu diễn mới. Ta có thể nhìn vào dữ liệu trong từng biểu diễn này và cách mạng phân loại chúng. Khi đến biểu diễn cuối cùng, mạng sẽ chỉ đơn giản vẽ một đường thẳng qua dữ liệu (hoặc trong không gian nhiều chiều hơn, một siêu phẳng).
Trong hình ảnh trực quan trước, ta nhìn vào dữ liệu ở biểu diễn “thô” của nó — tức là nhìn vào lớp đầu vào. Bây giờ ta sẽ nhìn vào nó sau khi được lớp đầu tiên biến đổi — tức là nhìn vào lớp ẩn.
Mỗi chiều tương ứng với sự kích hoạt của một nơ-ron trong lớp đó. Lớp ẩn học một biểu diễn sao cho dữ liệu có thể phân tách tuyến tính.
Trực Quan Hóa Liên Tục Các Lớp
Trong cách tiếp cận được nêu ở phần trước, ta hiểu mạng bằng cách nhìn vào biểu diễn tương ứng với từng lớp — cho ta một danh sách rời rạc các biểu diễn.
Phần khó là hiểu làm thế nào ta đi từ biểu diễn này sang biểu diễn khác. May thay, các lớp mạng nơ-ron có những tính chất tốt giúp điều này rất dễ dàng.
Có nhiều loại lớp khác nhau được sử dụng trong mạng nơ-ron. Ta sẽ nói về lớp tanh như một ví dụ cụ thể. Một lớp tanh $\tanh(Wx + b)$ bao gồm:
- Một phép biến đổi tuyến tính bởi ma trận “trọng số” $W$
- Một phép tịnh tiến bởi vector $b$
- Áp dụng tanh theo từng điểm
Ta có thể trực quan hóa điều này như một phép biến đổi liên tục.
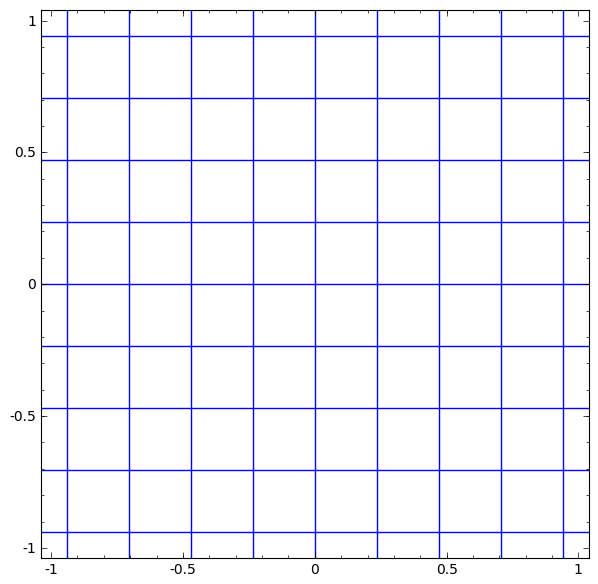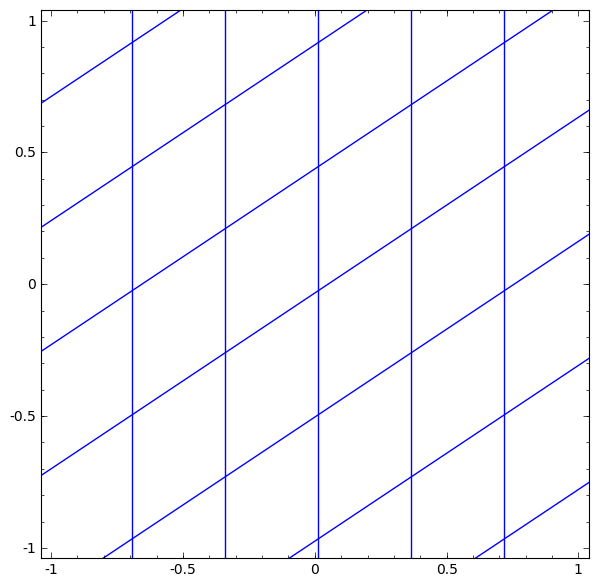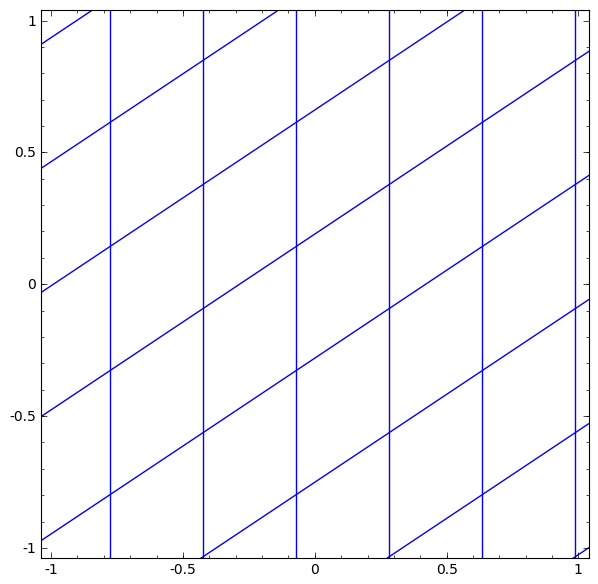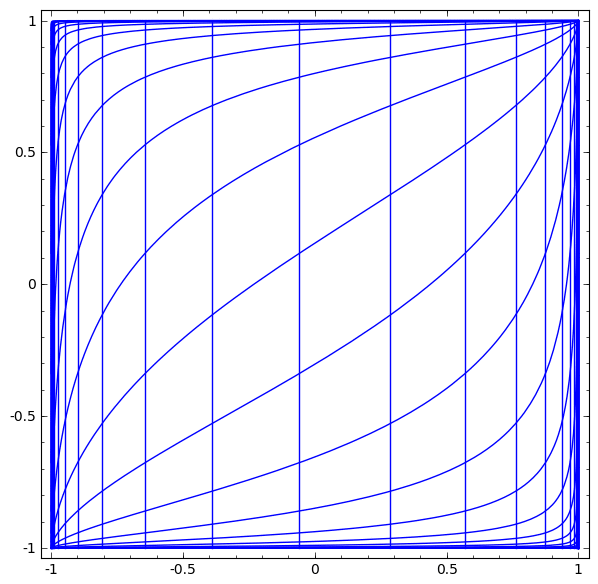
Câu chuyện cũng tương tự với các lớp chuẩn khác, bao gồm một phép biến đổi affine theo sau bởi việc áp dụng theo từng điểm của một hàm kích hoạt đơn điệu.
Ta có thể áp dụng kỹ thuật này để hiểu các mạng phức tạp hơn. Ví dụ, một mạng phân loại hai vòng xoắn hơi rối nhau bằng cách sử dụng bốn lớp ẩn. Theo thời gian, ta có thể thấy nó dịch chuyển từ biểu diễn “thô” sang các biểu diễn cấp cao hơn mà nó đã học để phân loại dữ liệu. Trong khi các vòng xoắn ban đầu bị rối, cuối cùng chúng có thể phân tách tuyến tính.
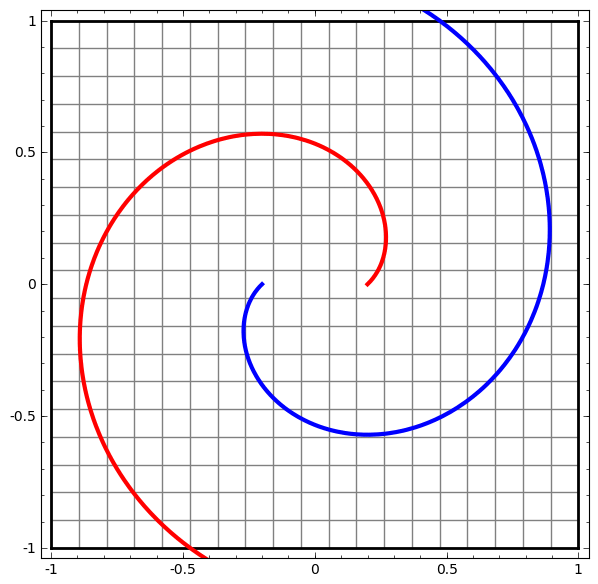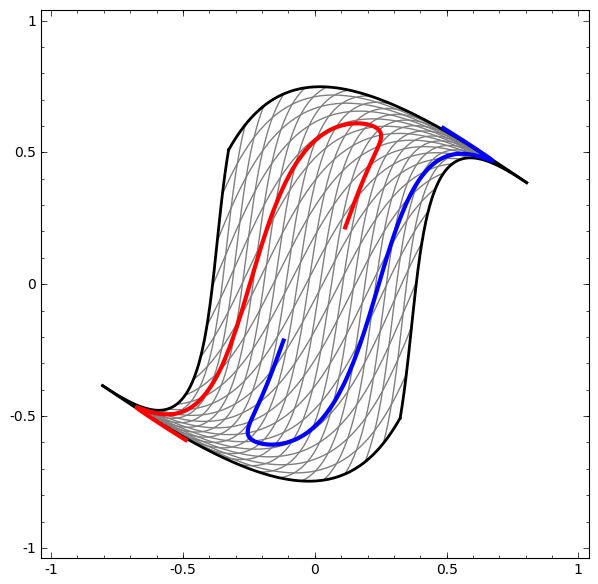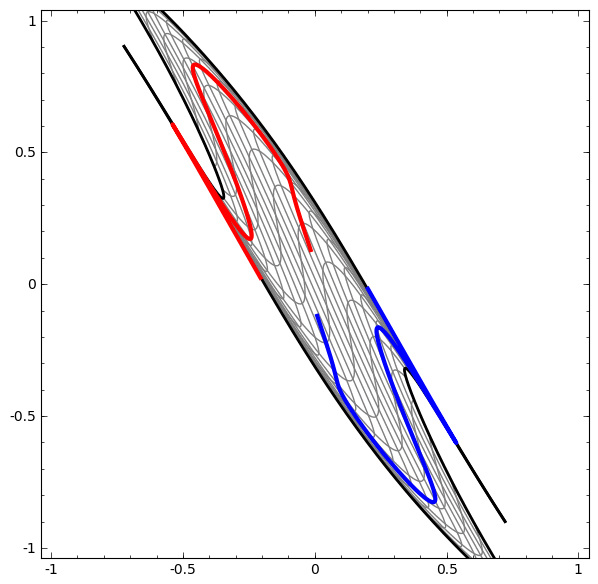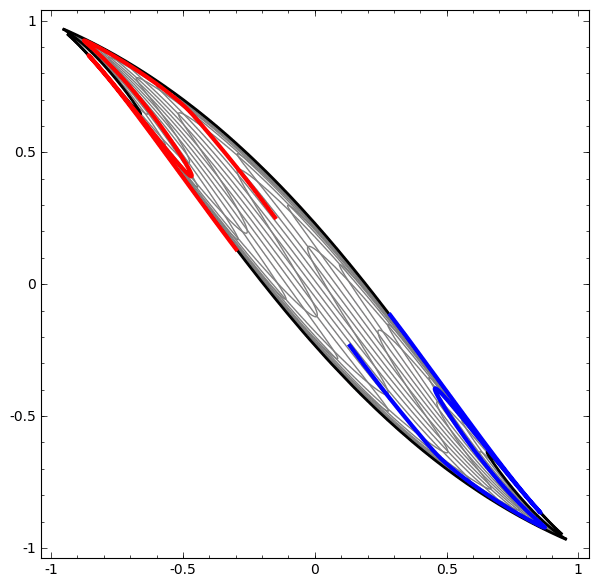
Mặt khác, một mạng khác, cũng sử dụng nhiều lớp, thất bại trong việc phân loại hai vòng xoắn rối hơn.
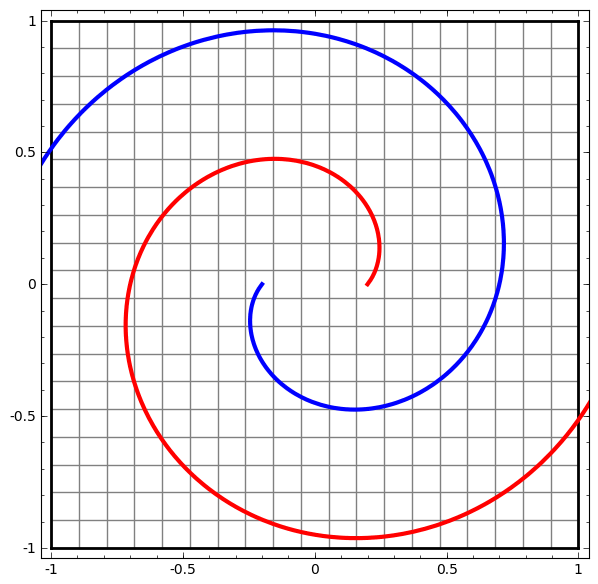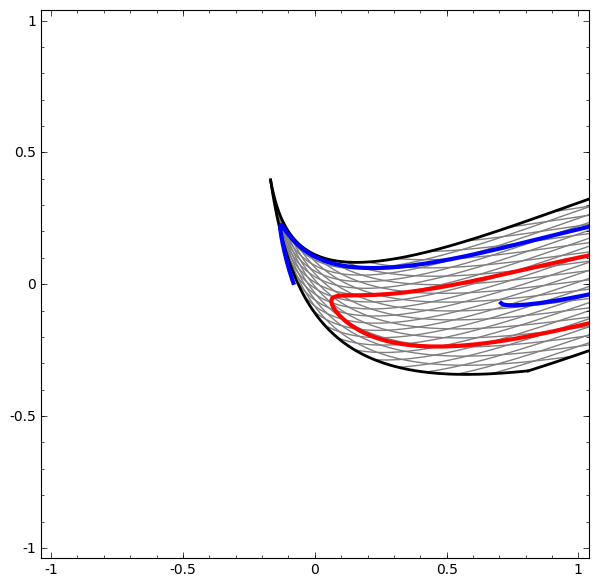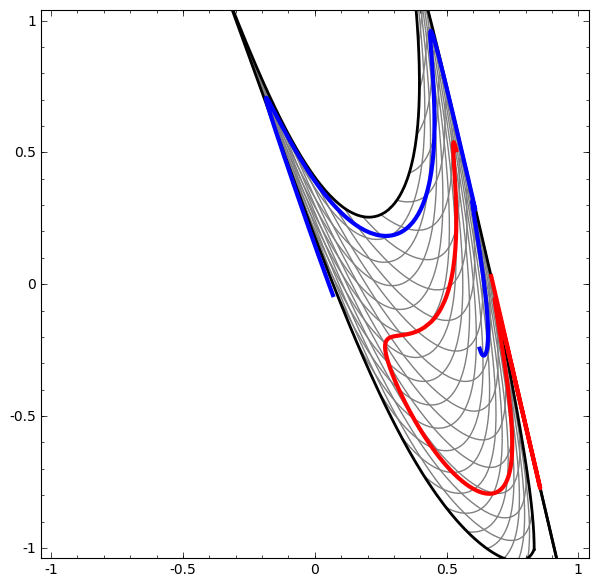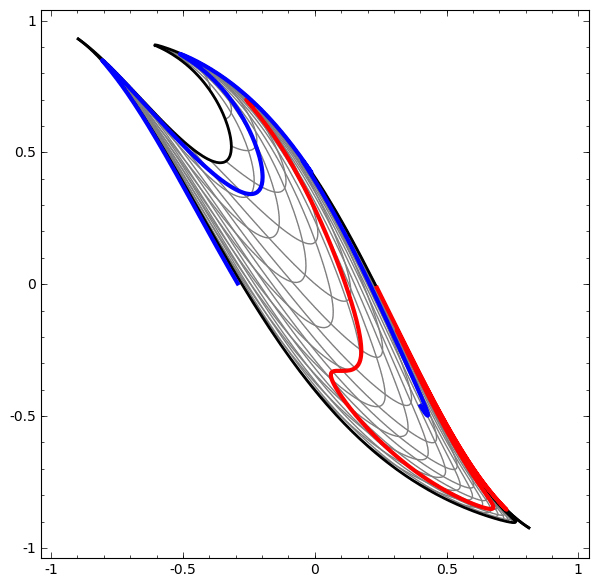 Đáng lưu ý rằng những bài toán này chỉ có phần nào thách thức vì ta đang sử dụng mạng nơ-ron số chiều thấp. Nếu dùng mạng rộng hơn, tất cả những điều này sẽ khá dễ dàng.
Đáng lưu ý rằng những bài toán này chỉ có phần nào thách thức vì ta đang sử dụng mạng nơ-ron số chiều thấp. Nếu dùng mạng rộng hơn, tất cả những điều này sẽ khá dễ dàng.
Tô-pô Học của Các Lớp tanh
Mỗi lớp kéo dài và nén không gian, nhưng không bao giờ cắt, phá vỡ hay gấp nó. Theo trực giác, ta có thể thấy rằng nó bảo toàn các tính chất tô-pô. Ví dụ, một tập hợp sẽ vẫn liên thông sau phép biến đổi nếu nó liên thông trước đó (và ngược lại).
Các phép biến đổi như thế này — không ảnh hưởng đến tô-pô — được gọi là đồng phôi (homeomorphism). Về mặt hình thức, chúng là các song ánh mà cả hai chiều đều là hàm liên tục.
Định lý: Các lớp với $N$ đầu vào và $N$ đầu ra là đồng phôi, nếu ma trận trọng số $W$ không suy biến.
Chứng minh: Xét từng bước:
- Giả sử $W$ có định thức khác không. Khi đó nó là một hàm tuyến tính song ánh với nghịch đảo tuyến tính. Các hàm tuyến tính liên tục. Vậy nhân với $W$ là một đồng phôi.
- Các phép tịnh tiến là đồng phôi.
- tanh (và sigmoid, softplus, nhưng không phải ReLU) là các hàm liên tục với nghịch đảo liên tục. Chúng là song ánh nếu ta cẩn thận về miền xác định và miền giá trị. Áp dụng theo từng điểm là một đồng phôi.
Vì vậy, nếu $W$ có định thức khác không, lớp của ta là một đồng phôi. ∎
Kết quả này vẫn đúng nếu ta hợp thành bất kỳ số lớp nào như vậy.
Tô-pô Học và Phân Loại
Xét một tập dữ liệu hai chiều với hai lớp $A, B \subset \mathbb{R}^2$:
\(A = \{x \mid d(x, 0) < 1/3\}\) \(B = \{x \mid 2/3 < d(x, 0) < 1\}\)
Nhận định: Không thể có một mạng nơ-ron phân loại tập dữ liệu này mà không có một lớp với 3 hoặc nhiều hơn các đơn vị ẩn, bất kể độ sâu.
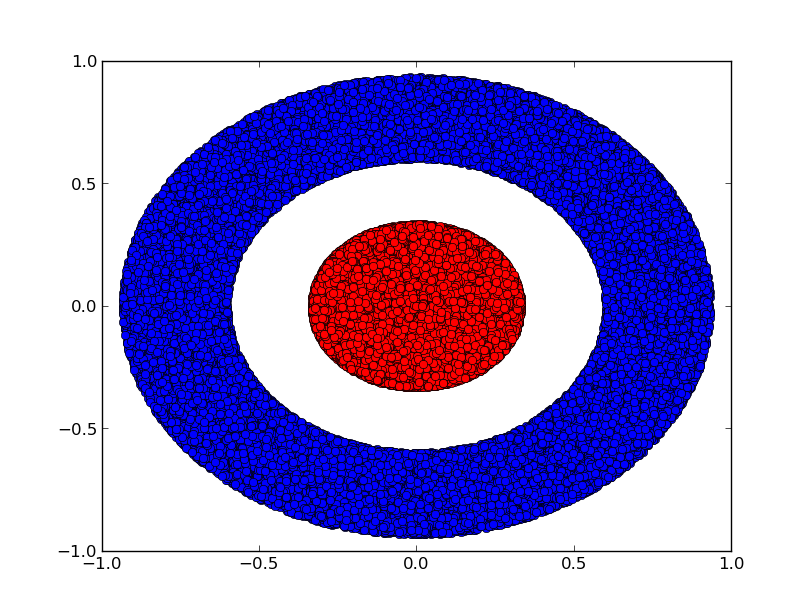
Như đã đề cập, phân loại bằng đơn vị sigmoid hay lớp softmax tương đương với việc tìm một siêu phẳng (hay trong trường hợp này là một đường thẳng) tách $A$ và $B$ trong biểu diễn cuối cùng. Với chỉ hai đơn vị ẩn, mạng về mặt tô-pô không có khả năng tách dữ liệu theo cách này, và chắc chắn sẽ thất bại với tập dữ liệu này.
Cuối cùng mạng rơi vào một cực tiểu cục bộ khá vô ích. Mặc dù, nó thực sự có thể đạt được khoảng 80% độ chính xác phân loại.
Chứng minh: Hoặc mỗi lớp là một đồng phôi, hoặc ma trận trọng số của lớp có định thức bằng 0. Nếu là đồng phôi, $A$ vẫn bị $B$ bao quanh, và một đường thẳng không thể tách chúng. Nhưng giả sử định thức bằng 0: khi đó tập dữ liệu bị sụp đổ trên một trục nào đó. Vì ta đang xử lý thứ gì đó đồng phôi với tập dữ liệu gốc, $A$ bị $B$ bao quanh, và việc sụp đổ trên bất kỳ trục nào có nghĩa là một số điểm của $A$ và $B$ sẽ hòa lẫn và không thể phân biệt được. ∎
Nếu ta thêm đơn vị ẩn thứ ba, bài toán trở nên tầm thường. Mạng nơ-ron học biểu diễn trong không gian 3D, và với biểu diễn này, ta có thể tách các tập dữ liệu bằng một siêu phẳng.
Giả Thuyết Đa Tạp
Điều này có liên quan đến các tập dữ liệu thực tế, như dữ liệu hình ảnh không? Nếu ta thực sự tin vào giả thuyết đa tạp, tôi nghĩ điều này đáng xem xét.
Giả thuyết đa tạp phát biểu rằng dữ liệu tự nhiên hình thành các đa tạp (manifold) có số chiều thấp hơn trong không gian nhúng của nó. Có cả lý do lý thuyết lẫn thực nghiệm để tin điều này là đúng. Nếu ta tin vào điều này, thì nhiệm vụ của thuật toán phân loại về cơ bản là tách rời một loạt các đa tạp bị rối nhau.
Liên Kết và Đồng Luân
Một tập dữ liệu thú vị khác cần xem xét là hai hình xuyến liên kết $A$ và $B$.
Giống như các tập dữ liệu trước ta đã xét, tập dữ liệu này không thể tách mà không sử dụng $n+1$ chiều — cụ thể là chiều thứ 4.
Các liên kết được nghiên cứu trong lý thuyết nút thắt (knot theory), một lĩnh vực của tô-pô học. Đôi khi khi ta nhìn thấy một liên kết, không rõ ngay liệu đó là một “không liên kết” (một loạt thứ bị rối nhau nhưng có thể tách nhau bằng phép biến dạng liên tục) hay không.
Nếu một mạng nơ-ron sử dụng các lớp chỉ có 3 đơn vị có thể phân loại nó, thì đó là một không liên kết.
Từ góc nhìn nút thắt, hình ảnh trực quan liên tục về các biểu diễn được tạo ra bởi một mạng nơ-ron không chỉ là một hoạt ảnh đẹp — đó là một thủ tục để gỡ rối các liên kết. Trong tô-pô học, ta gọi đó là một đồng luân xung quanh (ambient isotopy) giữa liên kết ban đầu và các liên kết đã tách.
Con Đường Dễ
Điều tự nhiên mà một mạng nơ-ron thường làm — con đường rất dễ dàng — là cố gắng kéo tách các đa tạp một cách thô sơ và kéo dài các phần bị rối mỏng nhất có thể. Mặc dù điều này sẽ không gần với một giải pháp thực sự, nó có thể đạt được độ chính xác phân loại tương đối cao và trở thành một cực tiểu cục bộ hấp dẫn.
Điều này sẽ biểu hiện như các đạo hàm rất lớn trên các vùng nó đang cố kéo dài, và các bất liên tục sắc nét gần như tức thời. Các hình phạt co rút (contractive penalties) — phạt các đạo hàm của các lớp tại các điểm dữ liệu — là cách tự nhiên để chống lại điều này.
Các Lớp Tốt Hơn để Thao Túng Đa Tạp?
Càng nghĩ về các lớp mạng nơ-ron chuẩn — tức là với phép biến đổi affine theo sau bởi hàm kích hoạt theo từng điểm — tôi càng cảm thấy thất vọng. Khó mà tưởng tượng rằng những lớp này thực sự tốt trong việc thao túng các đa tạp.
Điều cảm thấy tự nhiên với tôi là học một trường vector với hướng ta muốn dịch chuyển đa tạp, rồi biến dạng không gian dựa trên nó. Ta có thể học trường vector tại các điểm cố định và nội suy theo cách nào đó. Ý tưởng này được truyền cảm hứng phần nào từ hàm cơ số hướng tâm (radial basis functions).
Các Lớp K Láng Giềng Gần Nhất
Tôi cũng bắt đầu nghĩ rằng tính phân tách tuyến tính có thể là một đòi hỏi quá lớn và có thể không hợp lý đối với mạng nơ-ron. Theo một số cách, điều tự nhiên cần làm sẽ là sử dụng k láng giềng gần nhất (k-NN). Tuy nhiên, sự thành công của k-NN phụ thuộc rất nhiều vào biểu diễn mà nó dùng để phân loại, nên cần có biểu diễn tốt trước.
Trong một thí nghiệm, tôi đã huấn luyện một số mạng MNIST (mạng tích chập hai lớp, không dropout) đạt khoảng 1% lỗi kiểm tra. Sau đó tôi bỏ lớp softmax cuối và dùng thuật toán k-NN. Tôi có thể liên tục đạt được mức giảm lỗi kiểm tra 0.1–0.2%.
Điều tôi thực sự thích về cách tiếp cận này là những gì ta “yêu cầu” mạng làm có vẻ hợp lý hơn nhiều: ta muốn các điểm thuộc cùng một đa tạp gần nhau hơn so với các điểm của đa tạp khác, thay vì các đa tạp phải phân tách được bởi một siêu phẳng.
Kết Luận
Các tính chất tô-pô của dữ liệu, chẳng hạn như các liên kết, có thể khiến việc phân tách tuyến tính các lớp bằng các mạng số chiều thấp trở nên bất khả thi, bất kể độ sâu. Ngay cả trong các trường hợp về mặt kỹ thuật là có thể, như các vòng xoắn, điều đó vẫn có thể rất thách thức.
Để phân loại dữ liệu chính xác bằng mạng nơ-ron, đôi khi cần các lớp rộng hơn. Hơn nữa, các lớp mạng nơ-ron truyền thống dường như không giỏi trong việc biểu diễn các phép thao túng quan trọng của đa tạp. Các lớp mới, được thúc đẩy cụ thể bởi góc nhìn đa tạp của học máy, có thể là những bổ sung hữu ích.